|
Sie sind hier: Home > Produkte > Software > Zum Archiv > File-Carrier |
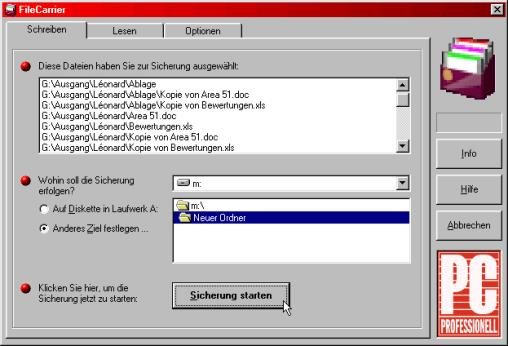
Dateien problemlos auf mehrere Datenträger verteilen:FileCarrier V1.1 - Flexibler Packer mit Freeware-DatenpresseDas Utility FileCarrier ist das ideale Tool zum Aufteilen und Transportieren großer Dateien oder ganzer Ordner mittels mehrerer Datenträger. Daneben zeigt das Projekt, wie man die Freeware-Packer-DLL zlib problemlos in eigene Utilitys integrieren kann.
Wie transportiert man eine Datei von einem PC zu einem anderen? Natürlich mit einer Diskette - sofern kein Netzwerk zur Verfügung steht. Was aber, wenn es sich um ein etwas größeres Winword-Dokument handelt, das zudem ein paar eingebettete Bilder enthält? Das schlägt nämlich leicht mit ein oder zwei MByte zu Buche, die dann nicht mehr so ohne weiteres an einem Stück auf eine Diskette passen. Hier gäbe es noch die Möglichkeit, die betreffende Datei mit einem Utility wie Winzip zu packen - bei Textdateien ergeben sich schließlich oft phänomenale Komprimierungsraten. Schafft man es jedoch nicht, die Dateigröße dadurch unter die Kapazitätsgrenze des Zielmedium zu drücken, so hat man ein echtes Problem. Zwar beherrschen fast alle modernen Packer die Aufteilung großer Datenmengen auf mehrere Datenträger. Doch fast immer steht allein die Komprimierung im Vordergrund - die Usability zur Lösung von Alltagsprobleme bleibt dabei jedoch auf der Strecke. Mehr Komfort durch den FileCarrier Dann legt man noch das Sicherungsziel fest, beispielsweise das Diskettenlaufwerk, und vergibt dem zu erstellenden Datensatz einen sinnfälligen Namen. Ein abschließender Klick auf die Schaltfläche Sicherung starten und das Backup beginnt. Sicherungsoptionen Anhand der Optionen auf der gleichnamigen Registerkarte kann zusätzlich noch festgelegt werden, wie groß die einzelnen Datenblöcke maximal werden dürfen. Dadurch hat man beispielsweise die Möglichkeit, einen kompletten Sicherungssatz für Disketten auf Festplatte anzulegen - den man anschließend auch ohne den FileCarrier beliebig oft duplizieren kann. In diesem Fall wäre also eine Blockgröße von rund 1400 KByte einzustellen. Ferner kann in den Optionen noch festgelegt werden, ob das Zielverzeichnis vor der Sicherung zu löschen ist - ein wichtiger Punkt bei Wechselmedien, die öfter mit dem FileCarrier verarbeitet werden. Wiederherstellung der Daten Hierfür werden die Archivblöcke nach und nach eingelesen, dekomprimiert und wieder zu einzelnen Dateien gemacht. Reicht ein Archiv über mehrere Datenträger, so wird am Ende des einen jeweils per Dialog nach dem nächsten verlangt. Trifft der FileCarrier bei der Wiederherstellung einer Datei auf ein gleichnamiges Objekt, so erhält man einen entsprechenden Hinweis. Man kann dann die Datei überschreiben, umbenennen oder auch einfach auslassen. Das Standardverhalten für diesen Fall lässt sich auf der Registerkarte Optionen festlegen. Dort kann man auch definieren, ob der ursprüngliche Verzeichnisbaum komplett wiederaufgebaut werden soll - oder alle Dateien in ein und dem selben Ordner landen sollen. Zlib - kompakt und schnell Einer dieser Packungskünstler ist die Bibliothek zlib. Sie ist der ideale Kandidat für eigene Projekte. Denn zlib ist kostenlos, berührt keinerlei Patente, und quasi auf jeder Plattform verfügbar. Letzterer Punkt ist besonders interessant: Dadurch können beispielsweise unter Linux mit zlib gepackte Daten problemlos auch etwa unter Windows wieder entpackt werden - und umgekehrt. Die in zlib verwendeten Kompressions-/Dekompressionsmethoden sind zudem recht schnell. Einen Vergleich mit anderen (kommerziellen) Packern braucht ein damit ausgestattetes Programm nicht zu scheuen. Zlib packt etwa so gut wie das aktuelle Winzip mit normaler bzw. maximaler Kompression. Dafür benötigt es aber deutlich weniger Zeit: Je nach Datenzusammensetzung sind Differenzen von 25 % bis 50 % möglich. Beim Entpacken sind die Unterschiede sogar noch deutlicher. Wichtig zu wissen ist auch, dass zlib nicht auf der LZW-Kompressionmethode aufsetzt. Diese hat nämlich den Nachteil, dass bei ungünstiger Vorgabe die Daten nicht schrumpfen, sondern gar anwachensen - in Extremfällen auf mehr als das doppelte der ursprünglichen Größe. Trifft zlib auf solch unverdaulichen Daten, so werden die Daten einfach nur gespeichert, anstatt sie großzukomprimieren. Im ungünstigsten Fall macht sich lediglich ein ein Verwaltungs-Overhead von 0,015 % der Ausgangsgröße bemerkbar - dazu gleich mehr. Auch zlib's Anforderungen an den Arbeitsspeicher können sich sehen lassen. Alles in allem werden für die Komprimierung rund 250 KByte benötigt, für das Entpacken sogar nur knapp 50 KByte. Wem dies für bestimmte Lösungen noch immer zu viel ist, kann die Bibliothek über deren Sourcen entsprechend umkonfigurieren. Allerdings hat ein geringerer Arbeitsspeicher auch direkte Auswirkungen auf die Komprimierungsrate von zlib, die dadurch etwas abnimmt. Zlib wurde von Jean-loup Gailly (Kompression) und Mark Adler (Dekompression) geschieben. Gailly ist unter anderem der Hauptautor des Unix-Tools gzip, welches auf zlib aufbaut. Adler hat ebenfalls an gzip mitgearbeitet, von ihm stammen zudem Programmteile in zip und unzip. Die Anwendung von zlib Alles in allem bietet die Bibliothek mehr als ein Dutzend Funktionen, darunter auch solche zum Lesen und Schreiben von .gz-Dateien. Eine Beschreibung im üblichen Sinne gibt es hierzu zwar nicht. Da aber der komplette Quelltext vorliegt, kann man sich im Handumdrehen mittels der Header-Files informieren. Für unsere Zwecke am interessantesten ist die Funktion compress() und ihr Gegenstück decompress(). Zusammengenommen ergeben sie ein universelles Werkzeug zum Komprimieren bzw. Dekomprimieren beliebiger Datenblöcke: Man übergibt einfach Adresse und Länge zweier Speicherbereiche - und nach dem Aufruf findet man den Inhalt des einen in komprimierter bzw. dekomprimierter Form im anderen vor. Declare Function compress Lib "zlib.dll" (dest As Any, destLen As Any, src As Any, ByVal srcLen As Long) As Long In dieser Form können für die Quell- und Zielbereiche (src und dest) sowohl Byte-Arrays als auch Strings verwendet werden. Der Parameter srclen gibt die Größe des Quelldaten in Byte an. Mit dem Wert in destlen informiert man die Funktionen über die Ausmaße des Ergebnispuffers. Letzterer Wert ergibt sich bei der Komprimierung aus der Summe von Ausgangsgröße und Verwaltungs-Overhead. Die Ausgangsgröße wird angenommen für den worst case, also den Fall, dass sich die vorliegenden Daten von zlib gar nicht komprimieren lassen. Das passiert beispielsweise, wenn die Daten eine für die verwendete Kompressmethode ungünstige Zusammenstellung haben oder ganz einfach schon komprimiert sind. Der Overhead berechnet sich wie folgt: Je 32-KB-Teilblock benötigt zlib 5 Byte für dessen Verwaltung. Hierzu kommen dann nochmals 6 Byte für das Handling des Gesamtblocks. Für die Komprimierung von beispielsweise 100.000 Byte sind also sicherheitshalber maximal 100.026 Byte zu reservieren. Beim Dekomprimieren ist die Berechnung des Ergebnispuffers einfacher. Dieser muss ganz einfach so groß sein, wie der betreffende Datenblock vor seiner Komprimierung. Wird beim Aufruf von compress() also nicht immer mit der gleichen maximalen Blockgröße gearbeitet, so ist die ursprüngliche Größe, in welcher Weise auch immer, zu sichern. Nach dem Ausführen von compress() bzw. decompress() werden die Werte für die Größe des Ergebnispuffers, sofern nötig, angepasst. Beim Komprimieren ist dies eigentlich fast immer der Fall, beim Entpacken so gut wie nie - es sei denn, man hat sich bei dem Ausgangswert vertan. Vereinfachte Anwendung Der große Vorteil dieser Funktionen besteht darin, dass man nur noch einen einzigen Parameter übergeben muss - nämlich den Puffer mit den zu behandelnden Daten. Das jeweilige Ergebnis wird dann in der gleichen Variablen geliefert. Um beispielsweise die Daten in dem String Zeichenkette zu komprimieren, genügt folgender Aufruf: Die Rückgabewerte aller vier Funktionen entsprechen übrigens denen von compress() bzw. decompress(). Download |
||||||||||||
Top |
© 2010 Wirth IT-Design |
Druckversion |
||||||||||